Snowflake Multi-Environment Architecture with Dev/QA/Prod Isolation
How to structure your Snowflake environments, roles, schemas, and permissions to support CI/CD, governance, and safe deployments.
DATA PLATFORM ARCHITECTUREADVANCED DATA ENGINEERING & IMPLEMENTATION
Kiran Yenugudhati
10/16/20242 min read
🎯 Why Environment Isolation Matters
A modern data platform must support:
🚧 Isolated development and testing
🔒 Secure production data access
🔁 CI/CD-friendly branching and deployments
🛠️ Modular pipelines with governance built-in
With Snowflake, it's possible to do all of this cleanly using zero-copy databases, role-based access, and warehouse isolation.
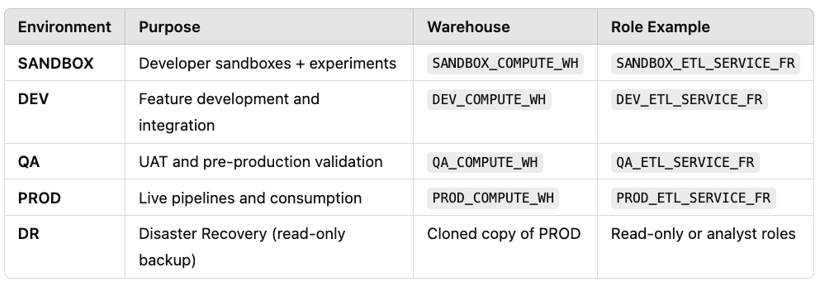
🧱 Snowflake Environment Strategy
We follow a 4-tier environment model, with an additional DR (Disaster Recovery) clone:
🔄 PROD Cloning
We clone PROD into SANDBOX, DEV, and QA when required
Ensures that developers and testers use the same data structure
Enables real-life testing without putting PROD at risk
Supports backtesting, model validation, and new logic prototyping
🧭 Environment Design Principles
✅ Consistent Schema Structure
All environments follow the same schema model:
<ENV>_ANALYTICS_DB.RAW
<ENV>_ANALYTICS_DB.BRONZE
<ENV>_ANALYTICS_DB.SILVER
<ENV>_ANALYTICS_DB.GOLD
This uniformity allows:
Reusability of dbt models and logic
Easy migration of features
Fewer surprises when deploying between stages
🔐 Role and Warehouse Isolation
We use dedicated roles and warehouses per environment.
🔹 Role Pattern
🔁 Chain: User → FR → AR → Environment-specific grants
🔹 Warehouse Strategy
Each environment has dedicated compute (e.g., DEV_COMPUTE_WH)
SANDBOX has standard + SPOT compute for cost control
Warehouses are sized based on environment purpose
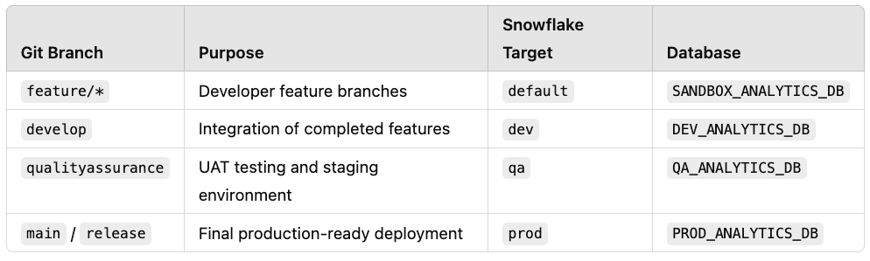
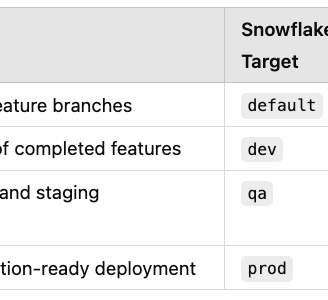
🔄 CI/CD Branching Alignment
We map Git branches directly to Snowflake targets:
This makes it easy to:
Test feature branches safely
Promote through environments via PRs
Automate deploys using dbt Cloud or GitHub Actions
🧩 Optional: RAW Layer for Custom Ingestion
If you're not using tools like Fivetran or Airbyte, you may want a dedicated RAW zone for custom ingestion pipelines.
Why Use a RAW Layer?
Store raw API payloads in VARIANT format
Reprocess or re-parse data without hitting external APIs again
Create structured bronze tables as needed
Example flow:
RAW → BRONZE → SILVER → GOLD
Learn More:
We've implemented this using Snowpark Python + dbt with a metadata-driven pattern.
🔗 Read the blog
Learn how to call REST APIs using metadata config, and generate flexible ELT pipelines.
✅ Summary
With this architecture in place, your Snowflake platform is ready to scale:
✅ Safe development environments
✅ Isolated production pipelines
✅ CI/CD support with Git-based workflows
✅ Role- and warehouse-based security
✅ Optional raw zone for custom ingestion and flexibility
This is the foundation for secure, governed, and enterprise-grade data platforms — without adding complexity.

ACTUVATE PTY LTD
Delivering strategic data architecture, cloud engineering, and AI-driven solutions
Connect
Insights
contact@actuvate.com.au
© 2024. All rights reserved.