Extracting Insights from Unstructured PDFs Using Snowflake Cortex LLM
Discover how to extract structured information from messy, unstructured PDF documents (like invoices, reports, or forms) using Snowflake’s Cortex LLM capabilities—no external tools or Python required. Ideal for operations, finance, and compliance use cases.
AI, ML & GENAIUSE CASES & MVP STORIES
Kiran Yenugudhati
2/23/20252 min read
This blog walks through how to extract structured data from unstructured documents like invoices, reports, or internal forms using Snowflake Cortex LLM. You’ll learn how to:
Process raw PDFs and extract useful content
Generate structured outputs (like JSON or table rows)
Use native LLMs in Snowflake — no external code or tools
Store results in Snowflake for reporting, automation, or compliance
🔍 Why This Matters
In nearly every business function — finance, legal, compliance, operations — valuable data is locked away in unstructured PDFs and emails:
Utility bills
Vendor invoices
Compliance reports
Contracts and policy documents
Internal forms or scanned records
Traditional extraction requires:
Python scripts
OCR engines
Manual copy/paste
Not anymore.
With Snowflake Cortex, you can now extract structured information from unstructured content entirely in SQL.
🧰 Prerequisites
To follow this approach, you’ll need:
Snowflake Enterprise Edition (with Cortex LLM enabled)
Access to a Snowflake stage to store/upload PDFs
Snowflake Cortex functions
Basic familiarity with Snowflake SQL
🛠️ Step-by-Step Guide
1. Upload PDF Files to Snowflake Stage
Upload your unstructured documents (e.g., PDFs) to a Snowflake stage:
This could be a monthly folder of utility invoices, legal reports, or any batch of documents you want to process.
2. Extract Raw Text from PDFs
If your PDFs contain extractable text (i.e., not scanned images), you can extract the raw content within Snowflake using UDFs or upload preprocessed text into a staging table.
3. Use Cortex LLM to Extract Structured Information
Use snowflake ML function's to extract fields from the document text. A sample prompt might look like:
“You are a document parser. Extract the following fields from this invoice: provider name, billing period, electricity usage (in kWh), gas usage (in MJ), total amount, due date. Return the result in JSON format.”
🛠️ Prompt templates and examples coming soon
🌱 Real-World Use Case: Sustainability Reporting from Utility PDFs
🔋 The Challenge
In Australia and globally, organisations receive monthly utility invoices in PDF format from energy providers. These documents contain:
Electricity usage (kWh)
Gas consumption (MJ or m³)
Site address
Billing period
Emissions intensity (optional)
Total amount
Manually entering these into spreadsheets is time-consuming and error-prone. The data is critical for:
Sustainability reporting (ESG, emissions tracking)
Finance audits and cost control
Automated alerting on abnormal consumption
✅ The LLM-Powered Solution
Using Snowflake Cortex:
Upload invoices to a stage (e.g., /utility_invoices/2025)
Extract text using Snowflake functions
Run an LLM prompt to extract key values into structured JSON
Store the results in a Snowflake table for downstream analytics
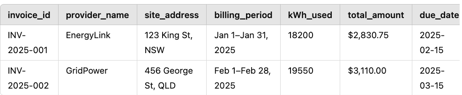
📊 Example Output Table
These results can feed into:
Dashboards showing monthly energy use
Carbon calculators estimating emissions
Alerts for spikes in usage
🧠 Prompt Engineering Tips
Keep prompts concise and use bullet-style output
Ask for specific formats (e.g. "return as JSON with these keys:...")
Add instructions like “Ignore boilerplate or payment instructions”
Tune prompts separately for electricity vs gas vs water documents if needed
🔐 Security & Governance
All document data stays within Snowflake — no third-party LLM required
Role-based access ensures only authorized users can access sensitive data
Prompts and responses can be logged for auditability
✅ Benefits of This Approach
Zero setup: no need for Python, OCR, or external services
Fast, scalable processing of high volumes of PDFs
Fully integrated with Snowflake + dashboards
Reproducible and secure — your LLM never leaves your data platform
📌 Conclusion
PDFs and unstructured documents don’t need to be a black hole anymore. With Snowflake Cortex LLM, you can:
Extract meaningful insights
Automate manual data collection
Power dashboards, alerts, and ESG reports
Enable finance and ops teams to move faster, smarter
Whether you're processing invoices, contracts, forms, or internal documents — this is your new superpower.
📎 Artefacts
Prompt templates for utilities, contracts, and finance docs
dbt model to automate ingestion + parsing pipeline
Streamlit UI to upload + preview LLM outputs
GitHub starter project for quick deployment
ACTUVATE PTY LTD
Delivering strategic data architecture, cloud engineering, and AI-driven solutions
Connect
Insights
contact@actuvate.com.au
© 2024. All rights reserved.